Hier ein praktisches Beispiel wie man den Parser von JOOQ verwenden kann. Gegeben sei ein String der einen Select enthält.
select name from books
Dieser soll aber mit Hilfe vom der JOOQ DSL um ein LIMIT und ein OFFSET von jeweils 10 erweitert werden.
Zunächst muss der Parser den String in DSL Objekt parsen, welches dann mit der DSL entsprechend modifiziert werden kann.
dsl.selectFrom(dsl.parser().parse("select name from books"))
.limit(10)
.offset(10)
.fetch();
Hinweis: Ein kleiner Nachteil ist, dass der Parser den SQL String verstehen muss. Zur Zeit werden noch nicht alle Feinheiten der diversen Dialekte unterstützt.
Weitere Einsatzmöglichkeiten
Da der Parser viele Dialekte versteht, kann man das SQL mit JOOQ transpellieren, dass heißt von den einem Dialekt in einen anderen transformieren.
Per default werden die Tabellen nach den Klassennamen und die Columns nach den Feldern benannt. Manchmal stört es einen oder es passt nicht zur der restlichen Struktur in der Datenbank.
Eine Custom NamingStrategy definieren
In diesem Beipsiel hat die Anwendung Tabellen die Über Hibernate verwaltet werden, sowie Tabellen die losgelöst davon im Schema vorhanden sind. Um diese Gruppen von Tabellen sauber zu trennen, kann man z.B. ein Prefix vor jeden Tabellenname einfügen und schon lassen sich schnell die Tabellen unterscheiden.
Tabellenname über @Table festelegen
Über die @Table Annoatation kann über den Parameter name der Tabellenname festgelegt werden. Dieses bietet natürlich größtmögliche flexibilität ist aber aufwändig, da jede Entität das angepasst werden muss.
@Table(name="hibernate_user")
Tabellenname über eine NamingStrategy festlegen
Wie oben beschrieben, wird es in den meisten Fällen nicht angebracht sein alles von Hand einzufügen. In Hibernate gibt es für den Zweck 2 Strategien, um die Generierung der Namen der Tabellen, Felder und Objekten zu beeinflussen. In diesem Beispiel interessiert uns die PhysicalnamingStrategy. Dazu implementieren wir das Interface PhysicalnamingStrategy wie folgt:
/**
* Adds a prefix "hibernate_" to all tablenames.
* @author sascha
*
*/
public class PrefixNamingStrategy implements PhysicalNamingStrategy {
@Override
public Identifier toPhysicalCatalogName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return name;
}
@Override
public Identifier toPhysicalSchemaName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return name;
}
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return stringToIdentifier("hibernate_" + name);
}
@Override
public Identifier toPhysicalSequenceName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return name;
}
@Override
public Identifier toPhysicalColumnName(Identifier name, JdbcEnvironment jdbcEnvironment) {
return name;
}
/**
* String to Identifier
*/
private Identifier stringToIdentifier(String name) {
return Identifier.toIdentifier(name);
}
Als Prefix habe ich hier hibernate_ hinzugefügt. Alle anderen Bezeichnungen werden 1:1 übernommen.
Einbindung über eine Bean
Damit die Strategy auch angewandt wird, muss diese gesetzt werden. Das kann man über die Properties oder eine Bean machen. Hier zeige ich kurz die Bean Variante:
@Bean
public PhysicalNamingStrategy physicalNamingStrategy() {
return new PrefixNamingStrategy();
}
Bei größeren Updates der Datenbank, kann es sein das sich auch Strukturen auf der Platte ergeben, so dass unter Umständen dann zu Fehler kommt. Zum Beispiel die MySql Workbench kann die Tabellen in den Schemata auf einmal nicht mehr lesen oder ähnliches.
Dann wird es spätestens Zeit die Strukturen anzupassen. Dazu bringt MySql und MariaDB das Tool mysql_upgrade mit. Auf der Konsole kann so einfach die Datenbankstruktur auf der Festplatte auf den aktuellen Stand angepasst werden.
mysql_upgrade -u root -p
Jetzt noch kurz das Passwort für Root angeben und kurz abwarten. Dann sollten auch alle seltsamen Fehler (siehe oben) verschwunden sein.
Nun fügen sich alle Puzzelteile zusammen und es läßt sich unter dem aktuellen LTS von Java, dem JDK 11, ein Beispiel mit Hibernate mit SQLite Datenbank, Jooq und Spring Boot 2.1 unter der Verwendung von Gradle als Buildsystem umsetzen. Bis hierhin gab es einige Baustellen, die im Zuge der Modularisierung (Projekt Jigsaw), noch zu beseitigen waren. Jetzt ist eine Umsetzung mit den aktuellsten Versionen möglich und dieses möchte ich hier vorstellen.
Hier die benötigten Komponenten im Einzelnen:
Spring Boot 2.1
Spring Data JPA (spring-boot-starter-data-jpa)
Jooq 3.11.4 (im Spring Boot Starter definiert)
Gradle 5.0-RC4
sqlite-dialect (Hibernate Dialekt)
sqlite-jdbc (Treiber)
Die Demo
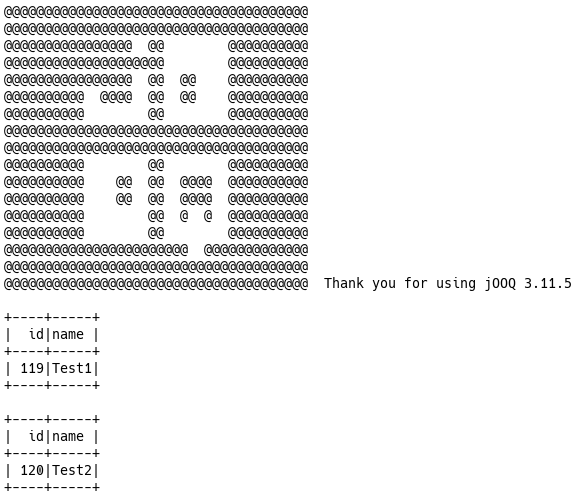
Die Anwendung erstellt zwei Invocation Objekte und persistiert sie mit JPA (Hibernate) in der Datenbank. Im Anschluss wird mit Hilfe von Jooq die Tabelle aus SQLite Datenbank wieder gelesen und in Tabellenform auf der Konsole ausgegeben. Das Ganze passiert in der Klasse InitDatabase, die das CommandLineRunner Interface implemenmtiert und somit beim Start der Anwendung ausgeführt wird. Die SQLite Datenbank legt die Daten in der Datei application.db ab. Eine initiale Version ist im Git Repository vorhanden (s.u.).
Ausführen der Anwendung
Der Build wird wie immer mit dem Dreisatz git clone, cd, ./gradlew clean build bootRun angestoßen.
git clone https://mrpeacockgit.duckdns.org:443/Public/spring-hibernate-jooq-sqlite-demo.git
cd spring-hibernate-jooq-sqlite-demo/
./gradlew clean build bootRun
Hier sehen wir den schön formatierten Output von Jooq auf der Konsole.
ACHTUNG: Es muss der Gradle Wrapper unter JDK 11 ausgeführt werden, weil Java 11 als Source- und TargetCompatibility angegeben ist. Wird Gradle z.B. unter Java 8 ausgeführt, dann bricht Gradle den Buildvorgang mit > Could not target platform: ‘Java SE 11’ using tool chain: ‘JDK 8 (1.8)’ ab. Hat man keine JDK 11 zur Hand, dann kann Source und Target auf Java 8 reduziert werden, da keine Sprachfeatures von Java 11 genutzt werden.
Import in Eclipse
Damit in Eclipse die Anwendung fehlerfrei ist, müssen 2 Schritte ausgeführt werden.
Generierung des Java Codes. Es muss die Generierung der Java Quelltexte, aus dem gegebenen Datenbankschema mit Hilfe des Jooq Code Generators, durchgeführt werden. Der Task generateSpringhibernatesqliteJooqSchemaSource wird von dem Jooq Plugin bereitgestellt.
Damit die statischen Importe gefunden werden, müssen sie auch im Eclipse Buildpath vorhanden sein. Dazu muss einmalig der Task eclipse ausgeführt werden.
Jetzt sollte das Projekt fehlerfrei im Eclipse sein.
Die Entität
Die Entity die hier verwendet wird, ist der Demo bedingt, sehr einfach gehalten. Wie immer verwende ich das Project Lombok, um den Code sauber von Boilerplate Code zu halten.
@Entity
@Data
public class Invocation {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private Long id;
private String name;
}
GenerationType
Der GenerationType muss hier auf AUTO stehen, ansonsten wird der Start der Anwendung mit einer Exception quittiert.
Caused by: org.sqlite.SQLiteException: [SQLITE_CONSTRAINT] Abort due to constraint violation (NOT NULL constraint failed: invocation.id)
Hibernate Schema Erzeugung / Jooq Code Generation
Hier haben wir ein Henne-/Ei-Problem! Der Code Generator von Jooq benötigt eine Datenbank aus der er das Schema ausliest, um den Code zu erzeugen. Im Quelltext wird aber bereits per Import auf generierten Code zugegriffen, was zu einer Fehlermeldung beim Kompilieren während des Builds führen würde. Da die Code Generierung vor der Kompilierung erfolgt, habe ich eine leere Datenbank mit in das Git Repository aufgenommen. Somit kann die Anwendung über den Gradle Build gebaut und auch ausgeführt werden.
Problem der automatischen Schema Generierung
Anhand des oben beschriebenen Henne-/Ei-Problems, sollte eigentlich jedem schnell klar werden, dass das keine Lösung für große Anwendungen ist. Es sollte hier besser auf andere Lösungsansätze ausgewichen werden. Z.B. Flyway als Datenbankschemamigrationstool oder einfach die Verwendung von Spring Boot Bordmitteln (Spring liest schema.sql ein und verarbeitet die SQL Anweisungen).
Jooq Konfiguration
Für das Erstellen der Konfiguration Jooq Code Generator wird das Plugin von Etienne Struder verwendet. Hier in den Beispiel ist nur eine Grundkonfiguration vorgenommen worden. Alle Einstellungsmöglichkeiten die möglich sind, lassen sich über das XSD für Jooq Code Generator erfahren. Das lesen und verstehen des recht umfangreichen XSD ist nicht einfach. Man kann aber z.B. über Visual XSD sich das XSD visualisieren lassen und so den Aufbau schneller verstehen.
Autovervollständigung in Eclipse
Bei der Eingabe in Eclipse werden nicht automatisch die statischen Imports für die generierten Tabellen von Jooq angezeigt. Hier muss man in Eclipse erst den Umweg über eine nicht statischen Import nehmen, um ihn dann per STRG + 1 in einen statischen Import zu überführen.
Beispiel
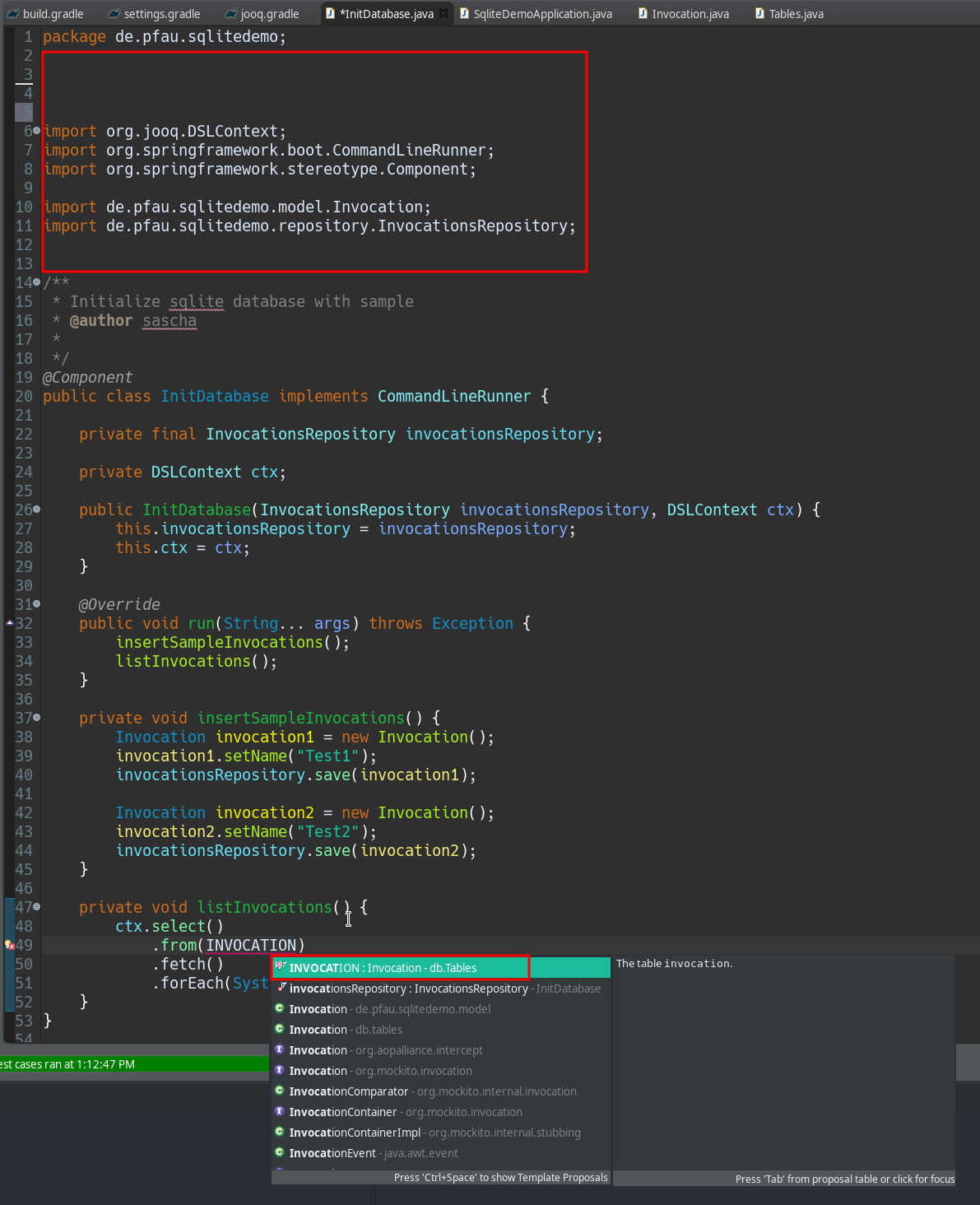
In der Klasse InitDatabase die den CommadLineRunner implementiert, möchten wir alle Invocations aus der Datenbank listen.
bekannt. Damit die Autovervollständigung funktioniert, muss der Import vorhanden sein. Das heißt erst nach dem man den Import eingefügt hat, lässt sich mit STRG + SPACE das Code-Fragment .from(INVOCATION) einfügen. Das ist nicht sehr effektiv, da man immer erst den Import einfügen muss.
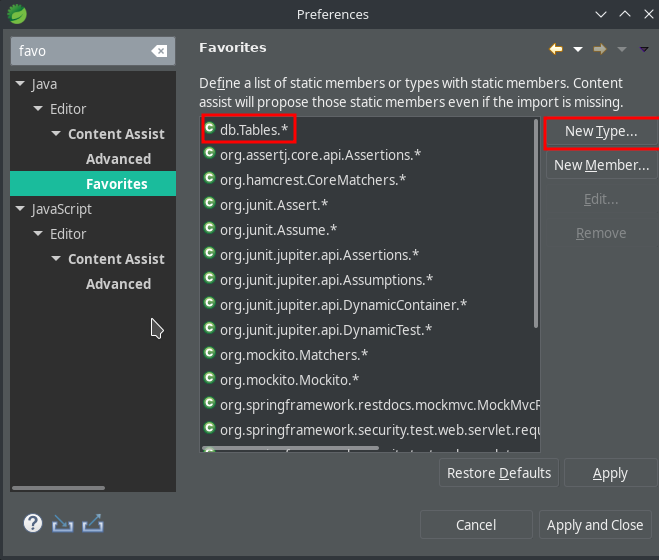
Einstellung der Favoriten
Der Generator von Jooq ist so konfiguriert, dass die Tabelle aus der Datenbank im Java Package de.Tables.* gelistet werden. Die Quelltexte werden außerhalb von main in src/db gespeichert, so dass jederzeit durch löschen von dem Verzeichnis src/db die generierten Quelltext sauber neu erstellt werden können, ohne das alte Artefakte noch verhanden sind.
Man kann Eclipse anweisen, bestimmte static Members anzuzeigen, auch wenn das Import noch fehlt. Und genau das führt hier zum Ziel und erleichtert die Eingabe von Jooq Queries mit der hervorragenden DSL enorm.
In den Präferenzen von Eclipse wählen Sie java –> Editor –> Content Assist –> Favorites und erstellen einen neuen Typen. Hier ist es *db.Tables.**.
Jetzt kann die Eingabe vervollständigt werden, ohne das der Import zuvor vorhanden war
Um Hibernate zur Zusammenarbeit mit SQLite zu bewegen, gibt es seit kurzem ein Release für https://github.com/gwenn/sqlite-dialect auf Maven. D.h. es kann direkt über Maven Central bezogen werden. Früher wurde das Programm nur über Jitpack.io verteilt, was zusätzliche Konfiguration im Buildskript erforderte.
Nun kann man die beötigten Abhängigkeiten mit 2 Zeilen hinzufügen:
Die Funktion NOW() gibt immer den Zeitpunkt aus an dem das Query gestartet worden ist. Daher liefert es auch nach 2 Sekunden Pause (s.u.) die gleiche Zeit.